Apr 26, 2024 9:29:05 AM
In the previous blog post, we introduced a definition for business real-time. This blog post will focus on how to process the source data to speed up the loading process and model the data to reduce the number of loads and joins without losing any data.
Data Ingestion
How you ingest the source system data is much more important than many think. Source data is integrated from source systems and placed in a cloud data storage such as Amazon S3, Azure Blob Storage, or Google Cloud Storage. However, especially when it comes to business real-time processing, the integrated source files need to be prepared before copying them from a cloud data storage to a staging layer in a data warehouse.
Here are a few of the most common pitfalls to avoid during data ingestion for business real-time processing.
Avoid tiny source files
The integrated files can be tiny. For example, in the case of transactional data, such as order data, each file may contain only one transaction, e.g., an order. Copying a large number of small files to a data warehouse takes several minutes or even hours. In a near real-time solution, this clearly is not sufficient, not to mention the impact on the data warehouse.
Preprocess your source data to an optimal format
The world is full of data formats, such as CSV, JSON, Parquet, and XML. However, not all data warehouse products support all the data formats. And even though the data warehouse product might support a given data format, end-to-end processing might be more efficient if you preprocess the data before copying it to the data warehouse. For example, flattening nested data in a data warehouse may require several distinct loads and tables (Picture 1). But doing the flattening in the cloud may require only one function and take significantly less time (Picture 2). Check your data warehouse product's documentation to get the complete list of things to consider when preparing the source files. (See, for example, [1, 2, 3, and 4])
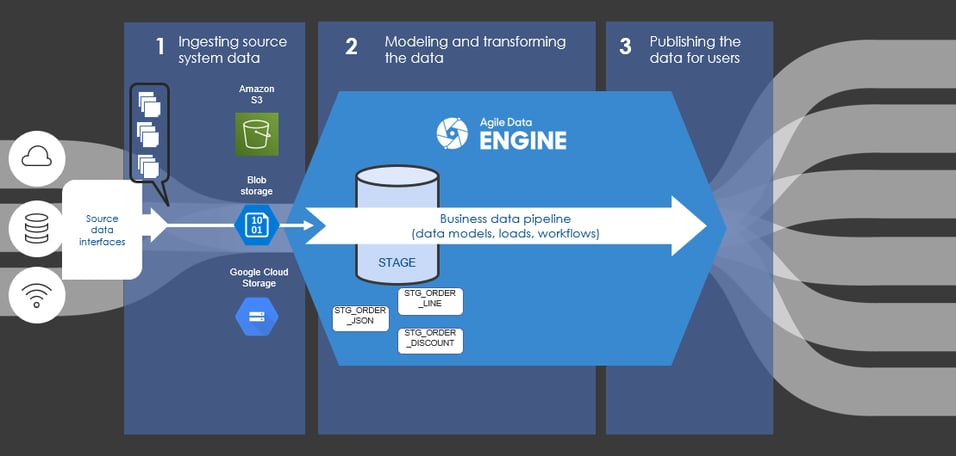
Picture 1. Ingesting process without preparation before staging layer in a data warehouse. Requires three staging tables and loads to flatten the data.
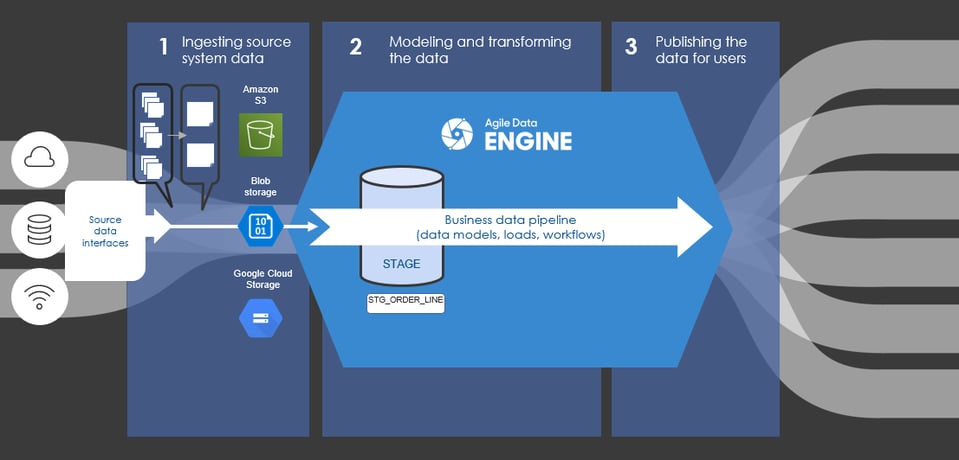
Picture 2. Ingesting process with preparation process in the cloud. Requires one function to prepare source files and one staging table.
How to optimize the data ingestion? An example solution
Consider the example data in Table 1. To help you decide the best way to prepare your source data files for the copy, check the best practices from your chosen data warehouse product's documentation.
You can do the data preparation by using, for example, serverless compute resources such as AWS Lambda, Azure Functions, or Google Cloud Functions. If possible, do all the preprocessing in one function to reduce the time spent triggering and starting new functions. Remember that you can still write modular code!
To reduce the number of files copied to a data warehouse, combine the source files containing single transactions into optimally sized files. Simultaneously, flatten the files to improve the processing in the data warehouse. You can see the results in Table 2.
.Without the flattening process, we would have needed three separate staging tables in the data warehouse; one for the JSON data, one for flattened order lines, and one for flattened discounts, as in Picture 1.
Table 1. Integrated source files before the preparation process.
| order1.json | order2.json | order3.json | ... |
| { "order_id":1, "order_time":"2022-02-22 20:20:02", "order_lines": [ { "order_line":1, "product": { "name":"red_product", "id":"1234" }, "order_quantity":1, "unit_price": 20.00, "unit_discount": 0, "total_price": 20.00 }, { "order_line":2, "product": { "name":"yellow_product", "id":"4321" }, "order_quantity":5, "unit_price": 10.00, "unit_discount": 0, "total_price": 50.00 }, { "order_line":3, "product": { "name":"green_product", "id":"1423" }, "order_quantity":20, "unit_price": 1.00, "unit_discount": 0, "total_price": 20.00 } ], "discounts": [] } |
{ "order_id":2, "order_time":"2022-02-22 20:20:20", "order_lines": [ { "order_line":1, "product": { "name":"yellow_product", "id":"4321" }, "order_quantity":8, "unit_price": 10.00, "unit_discount": 2.00, "total_price": 72.00 }, { "order_line":2, "product": { "name":"green_product", "id":"1423" }, "order_quantity":6, "unit_price": 1.00, "unit_discount": 0.10, "total_price": 5.40 } ], "discounts": [ { "order_line":1, "discount_code":54687 }, { "order_line":2, "discount_code":54687 } ] } |
{ "order_id":3, "order_time":"2022-02-22 20:20:22", "order_lines": [ { "order_line":1, "product": { "name":"green_product", "id":"1423" }, "order_quantity":10, "unit_price": 1.00, "unit_discount": 0, "total_price": 10.00 }, { "order_line":2, "product": { "name":"green_product", "id":"1423" }, "order_quantity":10, "unit_price": 1.00, "unit_discount": 0.10, "total_price": 9.00 } ], "discounts": [ { "order_line":2, "discount_code":54687 } ] } |
Table 2. Integrated source files after combining and flattening the data already in the cloud.
| order_id | order_time | order_line | product_name | product_id | order_quantity | unit_price | unit_discount | total_price | discount_code |
| 1 | 2022-02-22 20:20:02 | 1 | red_product | 1234 | 1 | 20.00 | 0 | 20.00 | |
| 1 | 2022-02-22 20:20:02 | 2 | yellow_product | 4321 | 5 | 10.00 | 0 | 50.00 | |
| 1 | 2022-02-22 20:20:02 | 3 | green_product | 1423 | 20 | 1.00 | 0 | 20.00 | |
| 2 | 2022-02-22 20:20:20 | 1 | yellow_product | 4321 | 8 | 10.00 | 1.00 | 72.00 | 54687 |
| 2 | 2022-02-22 20:20:20 | 2 | green_product | 1423 | 6 | 1.00 | 0.10 | 5.40 | 54687 |
| 3 | 2022-02-22 20:20:22 | 1 | green_product | 1423 | 10 | 1.00 | 0 | 10.00 | |
| 3 | 2022-02-22 20:20:22 | 2 | green_product | 1423 | 10 | 1 | 0.10 | 9.00 | 54687 |
| ... |
Data Modeling
When creating near real-time flows, keep the data processing as minimal as possible. For example, every new step, e.g., a join between tables, will consume the limited time available in business real-time processing.
When the inspected data arrive in the staging layer, it might be tempting to bypass the DWH layer and serve the data straight to the publish layer. After all, it would reduce processing and thus save time.
Don't skip the DWH layer!
In many cases, the ingested data is not ready to be published as such: the data structure might need to be changed, calculations might be required, and so on.
The data need to meet given conditions and business requirements. Otherwise, consumers cannot use it or combine it with other data from the data warehouse. Thus, if it is possible to use the DWH layer, use it! That way, the data gets saved into the persistent layer, and you get to handle two things at once. Remember to keep the model in the DWH layer as simple as possible, but make sure it can still store all the data, including history and changes.
Data Vault modeling with transactional links
When using the DWH layer in time-critical loads, you may not be able to rely on traditional modeling practices. In Data Vault, you usually divide the data into hubs, links, and satellites. Using those basic entities is a good practice, and I typically encourage using those. But, for business real-time processing, there are more efficient entity types.
One such entity type is a transactional link, also known as a non-historized link. People have mixed opinions on transactional links, but I think they really excel in near real-time processing.
Let's consider order data with a typical Data Vault model. There could be a hub for orders, a satellite for the hub, a hub for order lines, a satellite for that hub, and finally, a link between an order and order lines. Actually, there is one more entity; a link between an order line and a product. As a result, we need to load the data into seven different entities and join the data again in the publish layer using these entities (Picture 3). It doesn't sound very efficient.
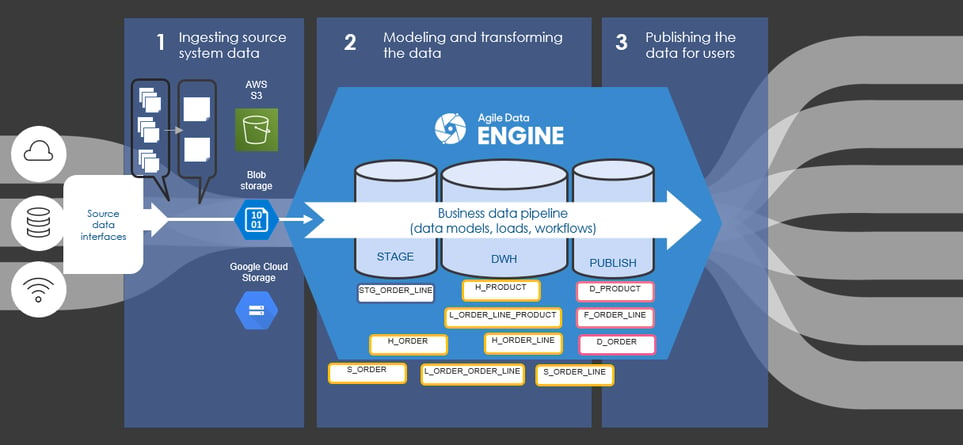
Picture 3. Data model without transaction link.
When we consider the publish layer, there is a fact for order line data. The granularity of the fact is the same as of the staging table. A business real-time solution most likely does not need the order dimension. With that in mind, the most important thing is to get the fact updated as quickly as possible. Then, the order dimension can be updated less frequently, and the processing can take more time.
How to achieve this using a transactional link? First, you need one transactional link: an order line containing all the order data. For business real time needs you only need to populate the order line entity in the DWH layer, and in the publish layer. (Picture 4)
In this case, the granularity of the staging table and the transactional link is the same: there is no need for an expensive grain shift. In addition, the granularity of the fact table in the publish layer is also the same.
All the descriptive data is stored in the transactional link, and the descriptive data shouldn't change. So if an order is changed, the system should cancel the original order and create a new one instead. Otherwise, the link needs a satellite, and the descriptive data needs to be placed on the link's satellite. That satellite is only one more entity in the DWH layer and one more join in publish layer, so it shouldn't slow down the processing too much.
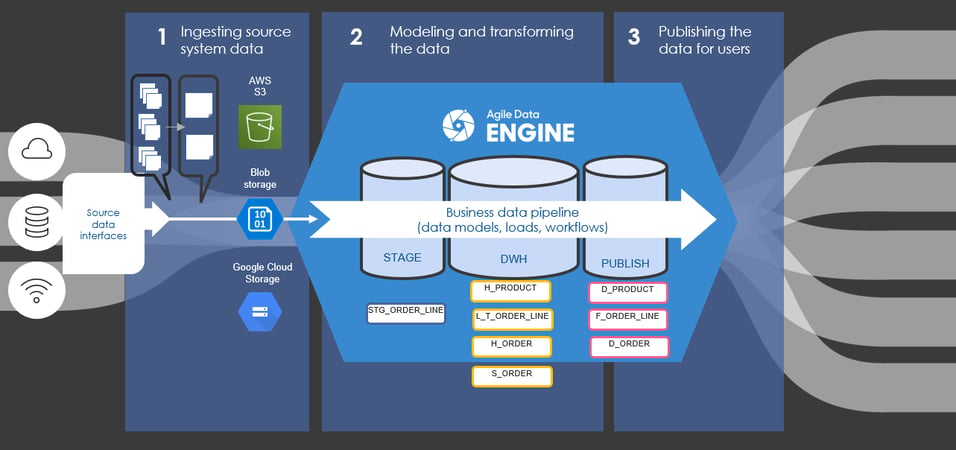
Picture 4. Data model with transaction link.
Enabling efficient data loads
Minimalist data modeling design (which does not mean any less time spent on the design 😉) that takes the granularity of the data into account is usually the source for efficient data loads. My next blog post will take a deeper dive into how to implement efficient data loads and transformations based on the data model design described here. Stay tuned!
References
[1] https://docs.snowflake.com/en/user-guide/data-load-considerations-prepare.html
[2] https://docs.aws.amazon.com/redshift/latest/dg/c_loading-data-best-practices.html
[3] https://cloud.google.com/bigquery/docs/batch-loading-data
[4] https://docs.microsoft.com/en-us/azure/synapse-analytics/sql/data-loading-best-practices