 By
·
3 minute read
By
·
3 minute read
Big data is getting bigger and faster. Our customers use data from several sources to guide their business-critical decisions in real-time. So naturally, they want to base these decisions on vast and up-to-date information. In this blog post, I will focus on business real-time data processing as a concept to tackle the increasing need for speed that data warehouses face today.
In recent years, the use of data to serve business-critical needs has skyrocketed. Companies continuously collect vast amounts of data, and they put that data to hard work. Five years ago, it was enough that the BI solution got updated data for a report overnight. Now, business needs to see aggregated and processed data within minutes of the transactions.
At the same time, the sheer volume of data has grown exponentially. To rise to the occasion, cloud data warehouses like Snowflake, Azure Synapse, AWS Redshift, and Google BigQuery are doing their best to always provide more efficient solutions with more capacity and enhanced computing power.
Despite the advancements, the fundamental laws of data processing still apply:
- Data processing takes time.
- Small batches of data are less cost-efficient to process per row than big ones.
So, how can we find the perfect balance between providing up-to-date data to business needs as often as possible and ensuring the performance and reliability of a data warehouse? I believe the answer lies in defining the concept of business real-time processing and optimizing your entire data flow from source to publish to meet that target.
What exactly is business real-time processing?
Business real-time processing refers to near real-time processing in a data warehouse. The concept emphasizes the importance of business involvement in the planning and implementation process. In business real-time processing, the benefit to the business and the cost and effort needed to implement and run the solution are in balance.
If you need to make decisions based on frequently changing data, two hours old or even older data may not support decision-making. For example, an e-commerce company monitors its stock and sale situation in near real-time. If - based on data, a product will be out of stock, you need to decide on time whether to buy more or not. In addition to current sales volumes, you can base the decision on previous sales volumes of the same product and product group and additional information such as the current or upcoming season.
Even if you could check the situation from an operational system, you cannot build the monitoring on top of it because the operational system is missing relevant data. Your data warehouse, however, contains all the needed data.
Traditional batch processing isn't sufficient either because the processing should take only minutes, not days or even hours. How fast the data needs to be available depends on the business. That is why we call this near real-time processing business real-time processing.
How does it differ from batch processing?
Experience has shown that similar data pipelines work with batch and business real-time data. However, you must implement each step with extra care. Each of the components may become a bottleneck. Source systems need to deliver or offer data timely. Data and file formats and even file sizes matter.
Your data model and loads play a crucial role in business real-time solutions. And the data warehouse itself has a central part to play: is it efficient enough to handle the usage? Finally, even if you have the best and most powerful components, the solution doesn't work if you can't orchestrate them to work together.
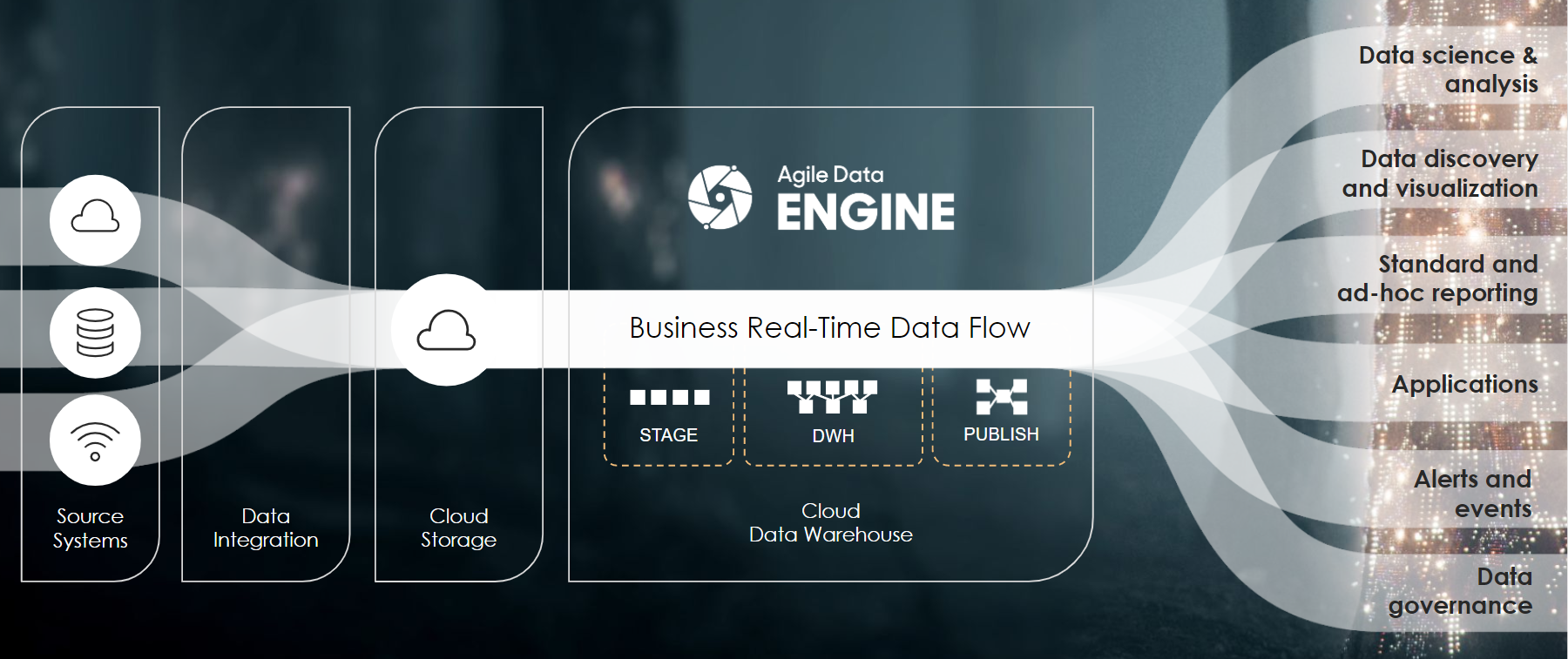 Data flow from sources to a data warehouse and finally to consumers. Designed for batch processing, but does it support near real-time processing?
Data flow from sources to a data warehouse and finally to consumers. Designed for batch processing, but does it support near real-time processing?
How to get started with business real-time processing?
All this might sound like too much. And right now, you might be wondering if it would be easier to give up before even starting.
If you are not prepared, the solution might become a nightmare. But with the right tools, competence, and ways of working, the implementation is not that hard. When you know what you are doing, you can enjoy the implementation process and be proud of the solution.
To achieve business real-time processing, you will need to optimize your entire data pipeline. At least the following questions will need to be addressed:
- Source Data Ingestion - How to process the source data to speed up the loading process?
- Data Model – What kind of data model supports the business real-time needs, and what data warehouse layers to use?
- Load Logic – How should you implement the loads and transformations of the ELT process?
- Orchestration – How to ensure that the solution works seamlessly and that the subsequent steps get started when the former ones are ready?
- Data Warehouse – What are the things the data warehouse needs to support?
We plan to answer all of the above questions in our upcoming blog posts. In the meantime, if you have a pressing need to implement a data solution that provides business real-time processing, we are happy to help you! Agile Data Engine provides the orchestration needed for business real-time processing out-of-the-box. In addition, our Professional Services consultants get their kicks by solving complex issues with our customers.
